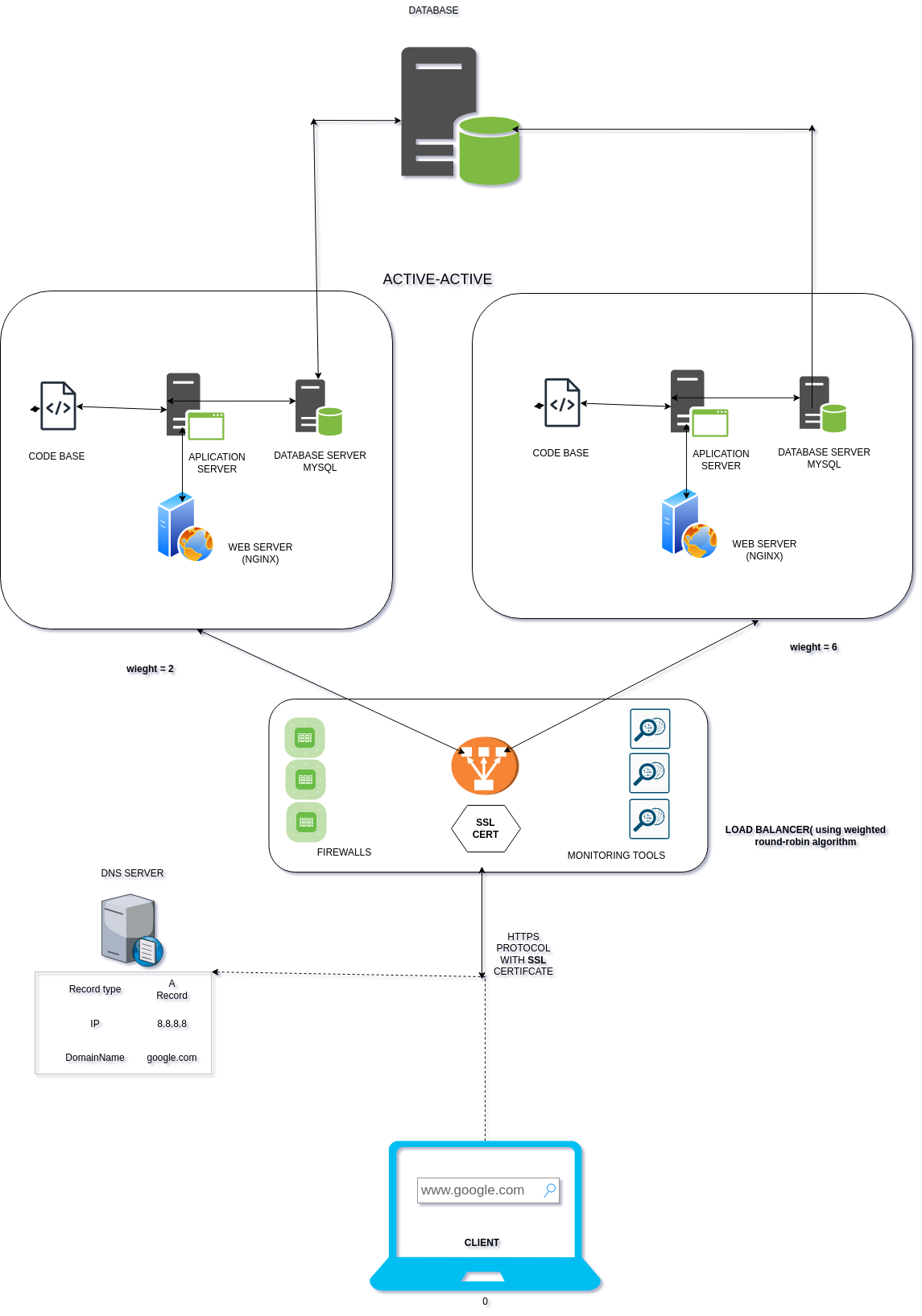
What happens when you type google.com in your browser and press Enter?

Software engineer student currently pursuing a degree in computer science and a passion for developing innovative software solutions
A network is a collection of computers linked together that communicate via some predefined standards known as protocols. The Internet in its current form is just a computer network - a collection of devices and computers linked together: this is known as the Internet. It is the backbone of our ability to share information globally, watch videos, and connect with individuals across vast distances. However, one may ask, what transpires behind the scenes? How does the transition from entering a web address to viewing content on our screens unfold? To illustrate this process, let's delve into a straightforward example: typing www.google.com into our web browser and hitting enter.
Servers
First, it's crucial to understand that since the Internet is a collection of computers, any information you request through your browser is already housed somewhere on another computer on the Internet. These specialized computers are commonly referred to as servers. Servers are dedicated machines (sometimes implemented as software) tasked with hosting information and responding with the right information when requested by a client (user). They are 'special' in that they're designed to operate continuously, 24 hours a day, and their enhanced resources facilitate this constant functionality. Typically, servers find their home in data centers, ensuring a consistent power supply and optimal environmental conditions. Therefore, typing `www.google.com` is typically saying, "I want to access this content". However, the challenge lies in the fact that your browser lacks knowledge about the precise location of this information among the multitude of interconnected computers on the internet. This is where `IP address` comes in.
IP address
Every computer on the internet is associated with a unique address, known as an `IP` (Internet Protocol) address. This specificity ensures that no two computers share the same IP address, so if there are 30 billion distinct servers, then there would be 30 billion IP addresses for each, respectively—an intriguing fact, right? The IP address serves as a means of identifying computers within the vast network of the internet. For instance, an IP address might look like `127.04.32.09`, or, in the newer IPv6 format, something likened to `fe80::4691:4853:7b43:f752%20`.
In the conventional approach, accessing information from platforms like `Google` or `Facebook` would necessitate remembering the specific IP address of their servers. However, this proves impractical, as IP addresses are not user-friendly or easy to memorize. To address this challenge, the concept of a 'domain name' comes into play.
Domain Name
Each server is assigned a distinctive name called a domain name. When you enter text into your browser, what you're typing is the domain name, not the IP address. For every IP address on the internet, there should be a corresponding domain name, facilitating user interaction without the need to grapple with the complexities of IP addresses. It's far simpler to remember google.com rather than a string of numbers like 127.0.38...
DNS (Doman Name System)
However, it's essential to recognize that domain names are essentially aliases. To pinpoint the actual location of a server, you require an authentic IP address. Herein lies the role of the DNS server. The DNS server, essentially another computer on the internet, is tasked with a straightforward mission: to take a domain name from your web browser and return the corresponding IP address. This process is facilitated by a 'DNS Resolver,' which first checks the local cache for the IP address—recently visited websites are often cached. If no match is found, the resolver proceeds to the Root DNS server, redirecting it to the Authoritative DNS server (also known as TLD - top-level domain). This intricate system constitutes the DNS server. Once the IP address is located during this search, the DNS server returns the IP address to the DNS resolver, which, in turn, hands it over to your web browser. Voila! You can now access the server - 'google.com'.
Web servers
In its fundamental operation, a web server fulfills requests by returning static content stored within it. This typically involves delivering HTML documents alongside other accompanying files. This process embodies a 'Client-Server' architecture, where the client requests information from the server, and the server, in turn, provides the requested information if it exists. If the requested resource is not present on the server, a '404' error page is returned, indicating that the sought-after content cannot be found. Yet, web servers don't operate in isolation; they are often hosted alongside additional servers, adding a layer of complexity. For instance, since a web server predominantly serves static content such as documents, images, and videos, a question arises: how can the web server respond to dynamic information, such as usernames, notifications, and personalized data specific to a user's request? This is where the integration of an Application server and a Database server becomes imperative.
Application and Database servers
An application server adds another layer behind a web server, working hand-in-hand with a database server. Dynamic information and business data, such as product details or user data, are typically stored in a database. When a web server needs to serve dynamic content rather than static content, it sends a request to the application server. The application server, in turn, requests the necessary data from the database server. Once this data is retrieved, the application server performs any necessary refinement or business logic on the data. Subsequently, the refined data is passed back to the web server, which combines it with the static content. The web server then responds to the client, providing information that is specific to the user. This collaborative process ensures that users receive personalized and dynamic content, enhancing the overall user experience. Sounds good, doesn't it? At this juncture, we've traversed almost the entire process from typing 'www.google.com.' However, the story doesn't conclude here. Like regular computers, servers may encounter challenges when handling a substantial influx of traffic. Consider a website with millions or even billions of users each day—a colossal demand for the server to respond to numerous requests. The repercussions? A compromised user experience, with information taking an extended time to load and users possibly unable to access the application altogether. So, how do we solve this issue? This is where a load balancer comes in.
Load balancers
A Load Balancer (LB) functions as an additional server within a web stack, with its primary role being to distribute traffic among two or more servers. Without a load balancer, multiple servers hosting the same application essentially operate independently. If traffic surges on individual servers, we encounter the same issues as with a single server. However, the introduction of a load balancer changes the game. Incoming requests are evenly (or according to a specified algorithm) distributed to prevent any single server from being overwhelmed. For instance, if we have three servers, the load balancer, depending on the chosen load balancing algorithm, will efficiently distribute incoming traffic among these servers. This proves highly beneficial for applications requiring high availability. Moreover, it introduces redundancy, eliminating the risk of a 'Single Point of Failure.' If one server encounters a failure, the load balancer promptly redirects traffic to other servers, ensuring the continuous operation of our application. This mechanism significantly enhances reliability and resilience in the face of server-related challenges.
Security - HTTPS/SSL
Additionally, securing web stacks involves implementing measures to ensure that messages exchanged between clients and servers are encrypted. This is accomplished through the installation of an SSL certificate on the server, coupled with the redirection of traffic from 'HTTP' to 'HTTPS' - a secured version of HTTP. But how does this security protocol function?
SSL, or Secure Socket Layer, acts as a powerful tool for encrypting information transmitted between clients and servers, utilizing a mechanism known as 'public and private key' encryption. The public key is openly shared with any client seeking information from the server, while the private key remains securely stored on the server. Messages encrypted with the public key can only be deciphered using the corresponding private key. Consequently, when users transmit sensitive information, such as passwords or credit card details, only the server possesses the capability to interpret the meaning behind the encrypted data. In essence, this implementation of SSL ensures that the communication channel between clients and servers remains confidential and secure, safeguarding sensitive user information from potential unauthorized access during transmission.

